Vul-RAG: Enhancing LLM-based Vulnerability Detection via Knowledge-level RAG
Update: July 24, 2024
Abstract
Vul-RAG: knowledge-level RAG
-
knowledge extraction:通过LLM从现有CVE中提取多维度knowledge
-
knowledge retrieval:对于给定代码片段,根据functional semantics从建立的knowledge base提取相关漏洞知识
-
vulnerability detection:根据检索到的knowledge,推断给定代码是否存在相似vulnerability causes & fixing solutions,判断给定代码片段是否存在漏洞
实验结果:在作者构建的benchmark PairVul中accuracy / pairwise-accuracy分别比所有baseline高出 12.96% / 110%,并且通过user study显示生成的vulnerability knowledge可以用于帮助提升manual detection准确率 (0.60 -> 0.77)。
Introduction
-
preliminary study: 测试不同方法的distinguishing capability,即区分vulnerable code和non-vulnerable code的能力,也即理解vulnerability-related semantics (high-level code semantics) 的能力。
“three representative learning-based techniques (i.e., LLMAO [8], LineVul [6], and DeepDFA [3]) along with one static analysis technique (i.e., Cppcheck [15])”
-
对于vulnerability-related semantics的定义(即本文提取的knowledge):“(i) the functionality the code is implementing, (ii) the causes for the vulnerability, and (iii) the fixing solution for the vulnerability.”
-
评估:
1)比较漏洞检测accuracy & pairwise-accuracy (vulnerable & non-vulnerable code pair 都判断正确) :分别比所有baseline高出 12.96% / 110%,
2)比较basic GPT-4, GPT-4 with code-level RAG & Vul-RAG:Vul-RAG最好;
3)user study比较有无vulnerability knowledge情况下,人工漏洞检测的准确度:0.60 -> 0.77。
Benchmark: PairVul
-
通过开源项目https://www.linuxkernelcves.com/收集linux kernel相关CVE ID
-
确认patch正确性:检查patch有没有被其他commit修改
Approach
Overview
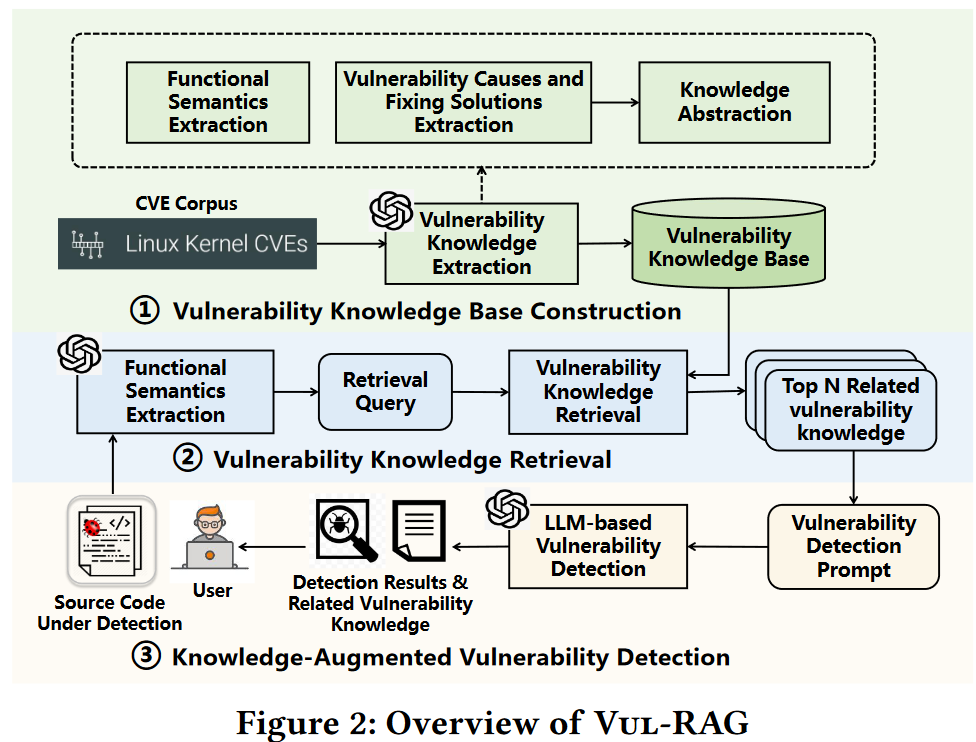
-
knowledge extraction: (CVEs)
-
functional semantics
-
vulnerability causes
-
fixing solutions
-
-
knowledge retrieval: functional semantics
-
vulnerability detection: vulnerability causes without solutions
Details
- 没有对functional semantics给出具体定义,直接依赖LLM总结的内容

Results
False Positives
-
在使用Vul-RAG的时候FP会比basic / code-based高
-
6.4分析的false positive的主要原因在于:1)mismatched fixing solutions,相似漏洞可以用不同方法进行修复,2)irrelevant vulnerability knowledge retrieval,有些knowledge description太过general(e.g., “missing proper validation of specific values”)
False Negatives
-
6.4分析的false negatives的主要原因在于:
-
inaccurate vulnerability knowledge description
-
unretrieved relevant vulnerability knowledge. 虽然有相似root cause和fixing solution,但是functional semantics不同。
-
non-existent relevant vulnerability knowledge. knowledge base中缺少相关Knowledge
-
Summary
总的来说,根据作者的分析,造成分析失败的原因主要是
-
大模型原因:GPT总结的不够好(主要是总结的Knowledge太general不够准确)
-
无法检索到相关knowledge(不太明白为什么会有root cause相同但是functional semantics不同的状况,作者也没有给出例子)
-
缺少相关Knowledge:a. 对于相同漏洞不同修复方法的Knowledge,b. 对于某种类型漏洞的knowledge
根据这些方面可能的future work在于:1)如何引导LLM进行更完善的总结(平衡具体漏洞和abstraction),2)检索方法增强,3) functional semantics分析方法增强